Guiding the Student's Learning Curve: Augmenting Knowledge Distillation with Insights from GradCAM
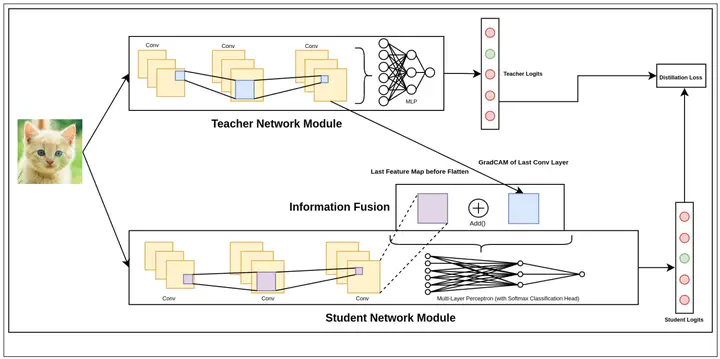 Image credit: Personal
Image credit: PersonalAbstract
In the pursuit of model compression techniques, Knowledge Distillation emerges as an effective strategy for developing compact neural network models. This approach primarily revolves around the minimization of a loss function that quantifies the disparity between the Prediction Logits generated by a larger Teacher network and those produced by a smaller Student network. In our research, we propose an enhancement to this method by incorporating the GradCAM (Gradient-weighted Class Activation Mapping) technique from the field of Model Explainability. This augmentation involves leveraging GradCAM as an additional input to the Student network for improved learning. Notably, our findings reveal that this approach facilitates expedited convergence, particularly when the Teacher network exhibits strong performance and a substantial size advantage over the Student network.
We ingest images as rank-4 tensors (B, H, W, C) and pass them in a parallel fashion to a Teacher Module and a Modified Student Module. The Teacher Module consists of a Convolutional Neural Network trained on a certain dataset. We extract a GradCAM Representation from the last Convolutional layer of the network. This representation is then passed on to the Student network as an input where it further undergoes information fusion at an intermediate level with feature maps. The Student network consists of another smaller Convolutional Neural Network. The Fusion module is placed right before the flattening section. The predictions from the Teacher network and the Student network are also used to generate a Distillation Loss. Other methods generally look to minimize a Reconstruction loss on the GradCAM representations extracted from the last Convolutional layers of the Teacher and Student network, but we diverge from this trend by passing the former as a separate input altogether. To solve the differences in size, we use an Upsampling in the form of a ConvTranspose operation.
Suvaditya Mukherjee
ML @ USC Institute of Creative Technologies & USC School of Cinematic Arts | MS CS-AI @ USC Viterbi | Google Developer Expert (Machine Learning)
My research interests include Computer Vision, Deep Learning, Generative Modelling, MLOps, and MLSys for optimizing inference.